Abstract
When assessing the quality of coding agents, predominant benchmarks focus on solving single issues on GitHub, such as SWE-Bench. In contrast, in real use these agents solve more various and complex tasks that involve other skills such as exploring codebases, testing software, and designing architecture. In this paper, we first characterize some transferable skills that are shared across diverse tasks by decomposing trajectories into fine-grained components, and derive a set of principles for designing auxiliary training tasks to teach language models these skills. Guided by these principles, we propose a training environment, Hybrid-Gym, consisting of a set of scalable synthetic tasks, such as function localization and dependency search. Experiments show that agents trained on our synthetic tasks effectively generalize to diverse real-world tasks that are not present in training, improving a base model by 25.4% absolute gain on SWE-Bench Verified, 7.9% on SWT-Bench Verified, and 5.1% on Commit-0 Lite. Hybrid-Gym also complements datasets built for the downstream tasks (e.g., improving SWE-Play by 4.9% on SWT-Bench Verified).
NO issue-solving, test-generation, or library-construction training data
Overview
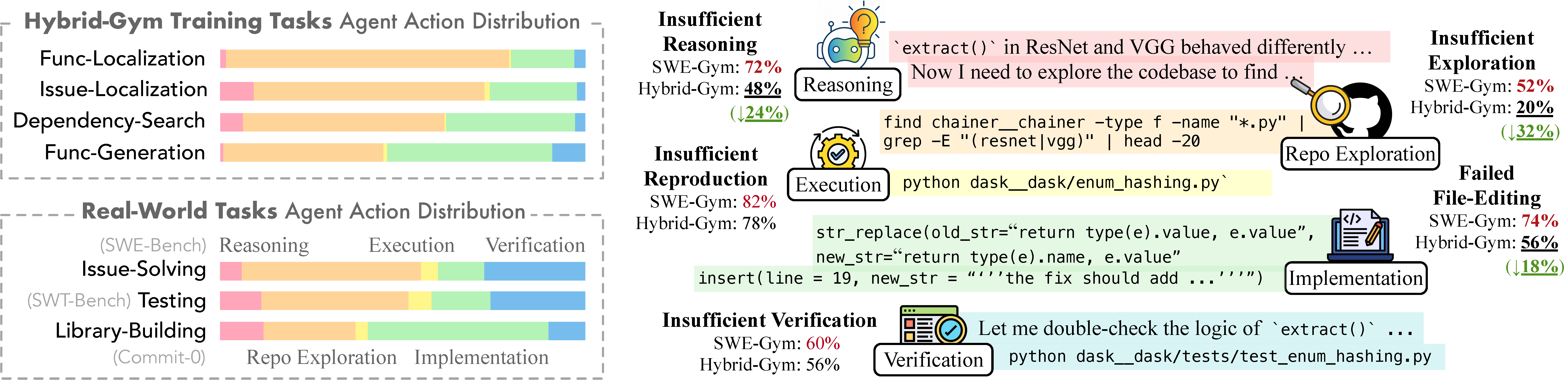
Left: Decomposition of coding agent tasks into intermediate components showing percentage of actions spent on each. Hybrid-Gym's training tasks cover reasoning, repository exploration, and implementation (~68% of actions). Right: Compared to baseline (SWE-Gym), training with Hybrid-Gym significantly reduces failures due to insufficient reasoning, insufficient exploration, and failed file editing, improving resolved rate on SWE-Bench Verified from 20.6% to 32.4%.
Hybrid-Gym Training Tasks
Hybrid-Gym consists of four scalable synthetic tasks designed to teach transferable coding skills without requiring executable repository setup.
Function Localization
Given a description of a function, locate it in the repository and write its docstring. Requires codebase exploration and code understanding.
Issue Localization
Given an issue description, localize the specific files, classes, functions, and lines of code that need modification to resolve it.
Dependency Search
Analyze a function and find all modules directly called by it within the repository, then annotate each dependency's definition.
Function Generation
Given a function signature and docstring, implement the function body by understanding surrounding code context and patterns.
Dataset Statistics
| Dataset | # Trajectories | # Repos | Avg Steps | # Docker Images | Cost / Instance |
|---|---|---|---|---|---|
| SWE-Gym | 491 | 11 | 40.2 | 2.4k | unknown |
| R2E-Gym | 3,321 | 10 | 33.2 | 4.5k | unknown |
| SWE-Smith | 5,016 | 128 | 26.7 | 128 | 2.32¢ |
| SWE-Play | 704 | 28 | 72.9 | 28 | unknown |
| Hybrid-Gym | 4,470 | 762 | 39.1 | 2 | 0.07¢ |
| — Func-Localize | 1,438 | 226 | 29.0 | 1 | 0.02¢ |
| — Issue-Localize | 1,978 | 263 | 52.4 | 1 | 0.00¢ |
| — Dep-Search | 502 | 120 | 26.9 | 1 | 0.00¢ |
| — Func-Gen | 552 | 306 | 28.6 | 1 | 0.56¢ |
Compared to existing datasets, Hybrid-Gym covers significantly more repositories (762 vs. ≤128) and requires only 2 Docker images, with per-instance cost 16× lower than SWE-Smith.
Main Results
Results on three real-world coding tasks. Hybrid-Gym achieves strong cross-task generalization without training on downstream tasks.
Qwen2.5Coder-32B
| Training Dataset | SWE-Bench Verified | SWT-Bench Lite | SWT-Bench Verified | Commit-0 Lite | ||
|---|---|---|---|---|---|---|
| Resolved % | Localized % | Non-Loop % | ||||
| Base Model | 7.0 | 45.6 | 70.6 | 9.42 | 9.01 | 8.34 |
| SWE-Gym | 20.6 (+13.6) | 57.8 (+12.2) | 76.2 (+5.6) | 3.26 (-6.16) | 2.77 (-6.24) | 9.58 (+1.24) |
| R2E-Gym | 34.4 (+27.4) | — | — | 3.26 (-6.16) | 4.39 (-4.62) | 11.56 (+3.22) |
| SWE-Smith | 40.2 (+33.2) | — | — | 13.77 (+4.35) | 10.62 (+1.61) | 12.38 (+4.04) |
| SWE-Play | 31.2 (+24.2) | 73.4 (+27.8) | 85.2 (+14.6) | 18.12 (+8.70) | 16.17 (+7.16) | 13.95 (+5.61) |
| Hybrid-Gym | 32.4 (+25.4) | 75.4 (+29.8) | 98.2 (+27.6) | 17.03 (+7.61) | 16.86 (+7.85) | 13.45 (+5.11) |
| Hybrid-Gym + SWE-Play | 33.6 (+26.6) | 75.2 (+29.6) | 99.2 (+28.6) | 20.29 (+10.87) | 21.02 (+12.01) | 15.52 (+7.18) |
Qwen2.5Coder-7B
| Training Dataset | SWE-Bench Verified | SWT-Bench Lite | SWT-Bench Verified | Commit-0 Lite | ||
|---|---|---|---|---|---|---|
| Resolved % | Localized % | Non-Loop % | ||||
| Base Model | 1.8 | 4.4 | 60.4 | 0.72 | 0.23 | 4.80 |
| SWE-Play-general | 8.6 (+6.8) | 49.2 (+44.8) | 93.4 (+33.0) | 2.54 (+1.82) | 1.62 (+1.39) | 9.25 (+4.45) |
| SWE-Gym | 10.6 (+8.8) | 48.2 (+43.8) | 79.0 (+18.6) | 1.45 (+0.73) | 0.69 (+0.46) | 8.61 (+3.81) |
| R2E-Gym | 19.0 (+17.2) | — | — | 0.72 (+0.00) | 0.46 (+0.23) | 9.25 (+4.45) |
| SWE-Smith | 15.2 (+13.4) | — | — | 0.00 (-0.72) | 0.00 (-0.23) | 9.32 (+4.52) |
| SWE-Play | 17.0 (+15.2) | 60.4 (+56.0) | 91.2 (+30.8) | 3.26 (+2.54) | 3.00 (+2.77) | 10.42 (+5.62) |
| Hybrid-Gym | 15.0 (+13.2) | 62.4 (+58.0) | 97.6 (+37.2) | 2.90 (+2.18) | 2.54 (+2.31) | 10.54 (+5.74) |
| Hybrid-Gym + SWE-Play | 17.6 (+15.8) | 58.6 (+54.2) | 97.2 (+36.8) | 5.07 (+4.35) | 4.39 (+4.16) | 11.02 (+6.22) |
Individual Task Analysis
Performance of training Qwen2.5Coder-7B on each Hybrid-Gym task individually. Function localization alone achieves larger gains than SWE-Gym (491 instances) on multiple benchmarks.
| Training Tasks (# Instances) | SWE-Bench Verified (%) | SWT-Bench Verified (%) | Commit-0 Lite (%) |
|---|---|---|---|
| Qwen2.5Coder-7B (Base) | 1.8 | 0.23 | 4.80 |
| + Issue-Solving (491) | 10.6 (+8.8) | 0.69 (+0.46) | 8.61 (+3.81) |
| + Func-Localize (500) | 12.8 (+11.0) | 3.00 (+2.77) | 8.74 (+3.94) |
| + Issue-Localize (500) | 9.6 (+7.8) | 2.31 (+2.08) | 9.09 (+4.29) |
| + Dep-Search (500) | 6.4 (+4.6) | 2.31 (+2.08) | 9.25 (+4.45) |
| + Func-Gen (500) | 7.8 (+6.0) | 2.54 (+2.31) | 9.25 (+4.45) |
| Hybrid-Gym Full | 15.0 (+13.2) | 2.54 (+2.31) | 10.54 (+5.74) |
Analysis
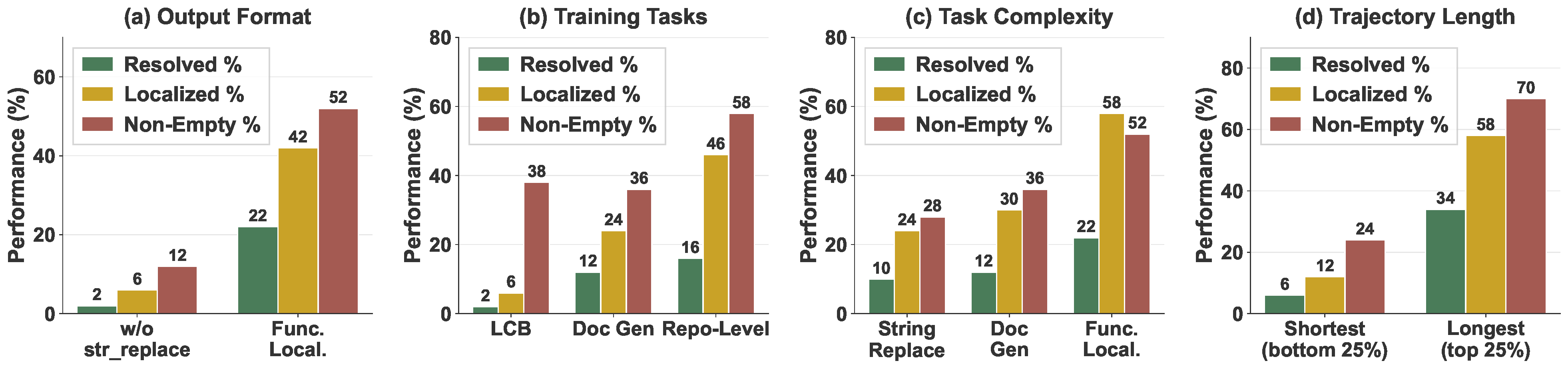
Controlled experiments on training data characteristics. (a) Output Format: Removing file editing actions from function localization trajectories causes large drop in SWE-bench resolution rate. (b) Repo-Exploration: Script-level code generation does not effectively transfer to repo-level issue-solving. (c) Task Complexity: Transfer improves as training tasks become more complex. (d) Trajectory Complexity: Training on longer trajectories substantially improves downstream performance.
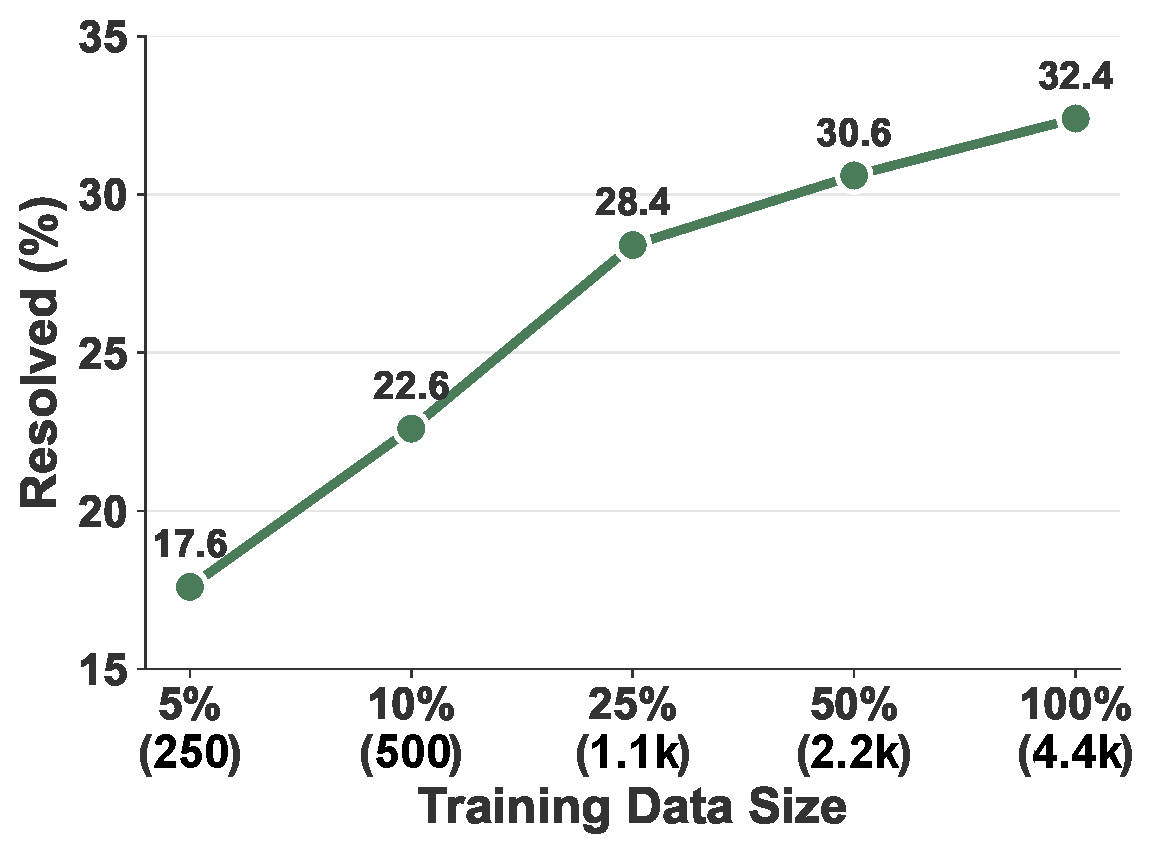
Scaling law analysis. Performance on SWE-bench Verified improves consistently as training data size increases from ~250 to 4.4k trajectories.
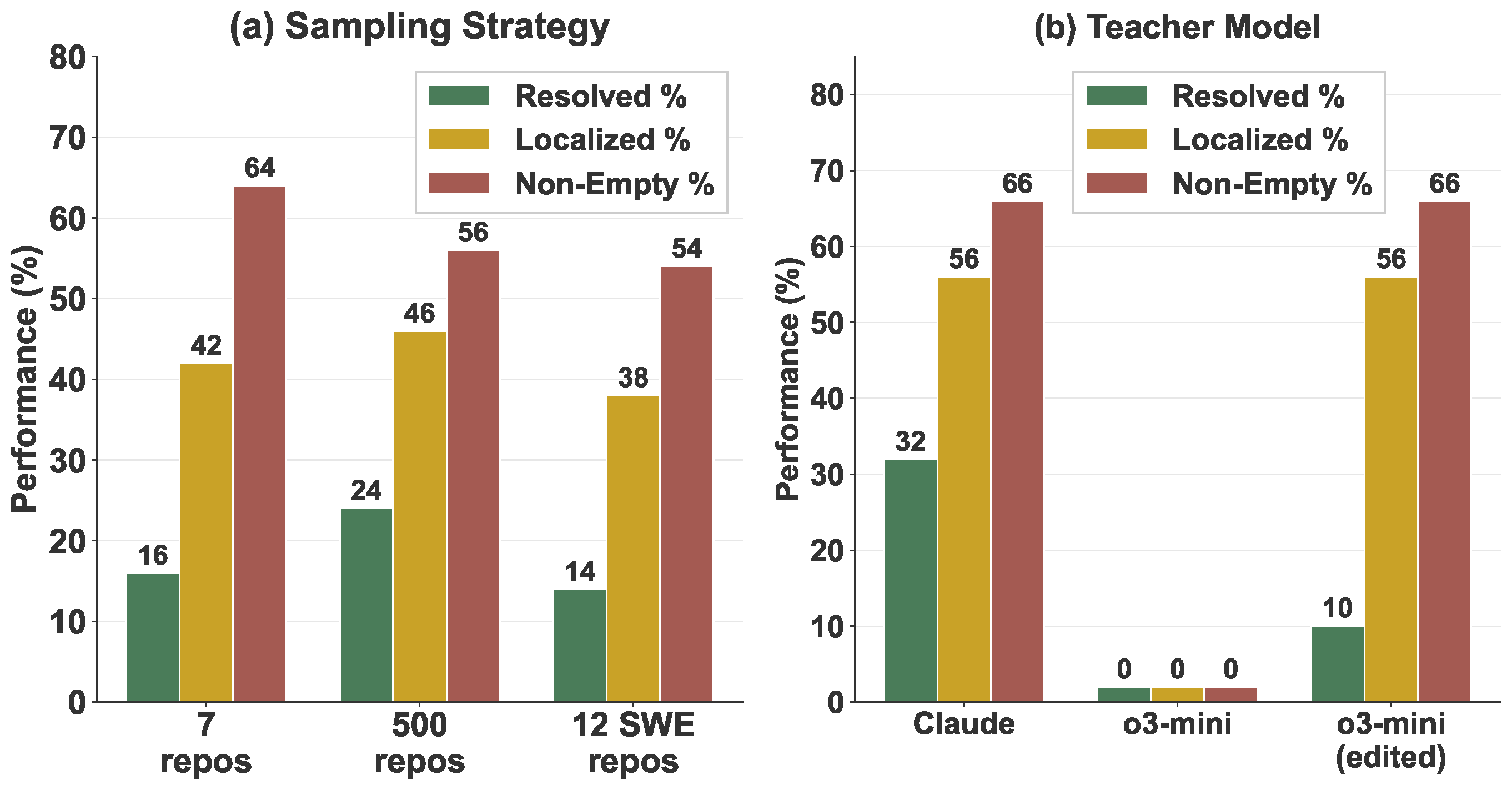
Effect of teacher model and data selection. (a) Repository diversity improves training but using same repositories as evaluation does not help. (b) Teacher model selection matters: different teacher models produce trajectories of varying quality.
BibTeX
@misc{xie2026hybridgymtrainingcodingagents,
title={Hybrid-Gym: Training Coding Agents to Generalize Across Tasks},
author={Yiqing Xie and Emmy Liu and Gaokai Zhang and Nachiket Kotalwar and Shubham Gandhi and Sathwik Acharya and Xingyao Wang and Carolyn Rose and Graham Neubig and Daniel Fried},
year={2026},
eprint={2602.16819},
archivePrefix={arXiv},
primaryClass={cs.SE},
url={https://arxiv.org/abs/2602.16819},
}